
Published on
March 22, 2026
The biggest question in spatial computing right now isn’t about hardware, it’s about integrating services: what’s the most effective way to bring dynamic, state-of-the-art AI into existing enterprise workflows and tools without compromising security or usability?
The landscape of professional VR training is changing fast. We’re moving away from static, pre-scripted interactions toward experiences that adapt to individual learners in the moment. In many training setups today, if a trainee asks a context-specific question, the system can only respond if that exact scenario was planned and scripted ahead of time.
This post breaks down how we brought AI into VR Builder so trainees can ask questions and get help in the moment. We’ll cover the approach we took, the results we saw, and the key pitfalls to avoid.
Through project AIXTRA, we integrated advanced AI speech capabilities, powered by Natural Language Processing (NLP) models, into a VR Training scenario. We didn’t add a default chatbot to VR space, we built a layer that helps teams move beyond static training experiences and create more flexible, multilingual learning content.
To realize this vision and to meet the non-negotiable data protection requirements of enterprise IT, we engineered a modular, self-hostable AI stack called AIXTRA, according to the research project name.
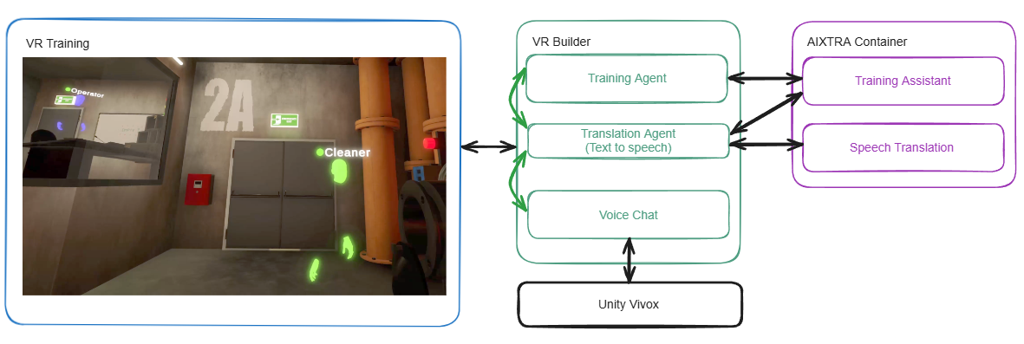
The AIXTRA architecture is built on a foundation of open-source models within a dockerized backend: one container for speech processing, one for the LLM-based requests, and a Text-to-Speech container. It allows the AI services to be hosted locally, on a private intranet, or across cloud providers like AWS or Google, entirely bypassing the IP-leakage risks associated with public consumer AI APIs. At its core, the system uses a best-in-class open-source models:
Integration for the end user is remarkably simple, AIXTRA is delivered as a single, plug-and-play Unity package. It connects on top of that, realtime voice channels like Unity Vivox with the AI components. This abstraction of machine learning complexity allows creators to focus entirely on the learning objectives rather than the underlying technical hurdles.
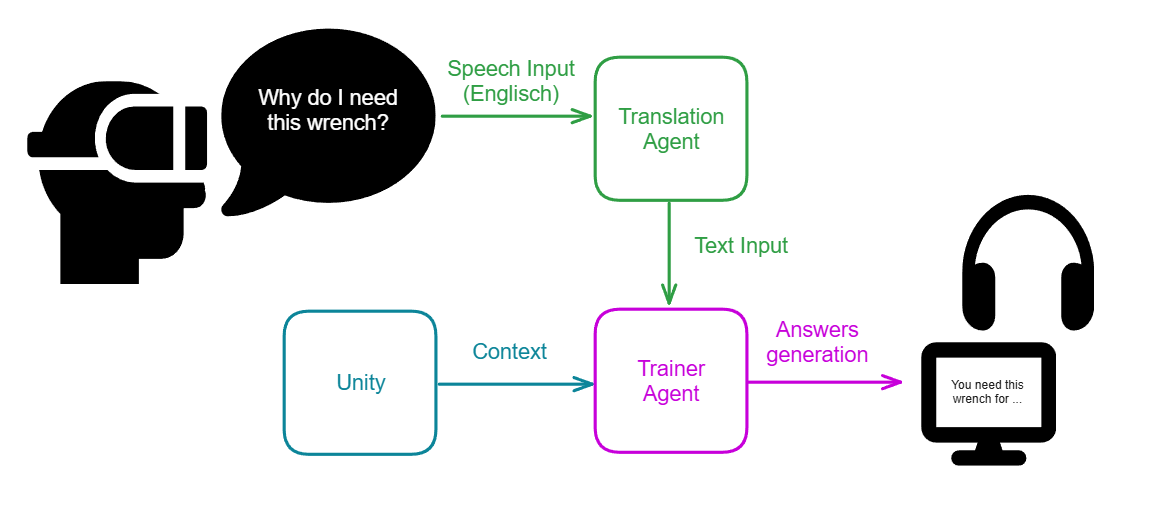
AIXTRA provides a global translation and training agent. The translation agent processes the audio stream of the user while the application runs. If the translation agent is done with the processing, the resulting data is provided to the training agent as a text input. The training agent collects the current scene context (like the current training step and instructions) and generates texts based on a predefined knowledge base. The generated answer is played live, over text-to-speech, to the user.
The true value of this integration lies in how we solved the two biggest friction points of AI in spatial computing: the problems of AI and LLM itself, such as hallucinations or misleading information and long latency.
The Latency vs. Immersion Conflict was one point we evaluated. In VR, presence is fragile. Early tests revealed that response delays broke user immersion. By modernizing the backend infrastructure and upgrading to optimized models like FasterWhisper-Large instead of just Whisper, we achieved massive performance gains, reducing average request-to-response times from a disruptive 3 seconds down to 500 milliseconds. Using stream based data transfer instead of request based start and stop recording also speeds up the request time. This increased transcription accuracy and directly bolstered user trust in the virtual agent according to our user study. Every project requires careful consideration of both quality and speed. If quality is the priority, larger AI models can help. However, if speed is the priority, it is necessary to switch to more modern hardware or hosting solutions, or to use smaller (more modern) models. The AI market is changing so rapidly that adjustments must always be planned.
Taming the LLM was the second point, which was very hard to solve. A major risk in AI is hallucinations, the AI giving confident but incorrect instructions, wrong answers or false information while answering requests. To solve this, we implemented a state-of-the-art Retrieval-Augmented Generation (RAG) inspired pipeline. Instead of relying on a single prompt, we use a multi-layer query system. When a user speaks and requests something, a vector-based semantic search returns the direction of the request. The LLM then gets an information feed of the scene context that includes scene information, the current training step, the provided training instruction and the given knowledge base. The output is passed through multiple strict guardrail layers before handed over to the translation agent to convert the answer to speech. The AI is forced to execute commands or answer questions directly related to the active training step or the current training context, or provides only information that is related to the knowledge base. Trainees can’t ask about the current weather, or ask about a joke.
The result of this agent based system and integration results into 13 new building blocks, including behaviors and conditions added directly to VR Builder’s visual editor. These blocks allow developers to create logic for features like intent recognition, LLM requests, and custom prompts through a simple drag-and-drop interface, with all server communication handled automatically in the background.
In a practical training scenario, a trainee might ask, "Where is the wrench?" or "What is the next step?". The AI training agent evaluates the user’s spoken intent alongside the current scene context to provide immediate, spoken instructions in the user's native language. In multi-user settings, the translation agent acts as a live mediator, transcribing and translating voice data in real-time so that an operator and a cleaner can coordinate a complex task even if they speak different languages. We found that 8 of 10 participants in multi-user studies felt well understood by their team through this real-time translation.
The risk of high latency and how users react to this. We are sharing these challenges and our exact solutions as actionable takeaways for any organization attempting to bridge the gap between Large Language Models and XR hardware. It is a common misconception that integrating AI into spatial computing simply requires pasting a public API key into a Unity script. In reality, building an enterprise-grade, reliable AI system inside a 3D environment is incredibly complex.
In XR, waiting for processing kills presence. If you are building AI for VR, optimize your stack for streaming chunks and edge-inference. A smaller, highly optimized model that delivers audio in milliseconds is infinitely more valuable for spatial immersion than a massive model that takes seconds to respond.
Language models should never block industrial processes. Our RAG pipeline proved the problem by using LLM solely to answer the user input. And we needed months for testing and trying out edge cases to fix them, roughly 15% of the whole project time. The last part of the integration phase must be the testing phase of the AI system. Try to break your system, try to force the LLM to give wrong answers. There must be enough time to evaluate every potential risk by using AI in such critical training areas. Feedback from end users running a trial run helps to identify weaknesses in the system.
The last point is about the AI usage itself. The AI based prototype is useless if enterprise IT departments veto it over data privacy. Companies will not stream proprietary CAD data, sensitive medical data or employee voices to public cloud infrastructure. Self-hostable, air-gapped architectures are not a nice-to-have feature, they are a prerequisite for B2B XR deployments for companies that really care about data privacy and data security.
The final phase of the project consisted of a structured user study to validate AIXTRA’s research objectives. Results were overwhelmingly positive: participants achieved a 100% completion rate in single-user training, demonstrating that the AI-based trainer can guide users through complex maintenance tasks without requiring a human trainer.
Furthermore, 91.6% of users reported that their trust in cross-language communication was strengthened by the real-time translation features, despite high initial skepticism about AI accuracy and AI in general. From a developer's perspective, the impact is even more dramatic, with professional XR developers reporting being 4 times more productive compared to their traditional XR development workflows by integrating AI themself into applications. Tasks that typically required months of specialized AI development can now be completed in weeks using our pre-built components.
Our study indicates that trust in AI is shaped more by functionality than by form. Although most participants expressed significant privacy concerns, they were pragmatically willing to trade some degree of data privacy for improved functionality when it resulted in better AI responses, which indicates that quality and response times are a huge factors for user experience. Balancing quality, data protection, and user experience should always remain important. At the same time, our study results reinforce the importance of a privacy-first architecture, particularly one that avoids transferring sensitive data to the cloud. Such an approach is likely essential for broad adoption in high-security domains such as healthcare and industrial production.
By addressing the current user needs for data privacy, ease of use, and dynamic interaction, we have transformed VR Builder from a static authoring tool into a global platform for inclusive, intelligent training.
AIXTRA doesn't just add a feature, it provides a foundational capability that makes advanced VR training accessible to every organization, regardless of their internal AI expertise. The lessons we have learned in latency optimization, hybrid intent recognition, and the necessity of self-hosted architectures provide a blueprint for any team looking to integrate AI into existing enterprise products.
Contact us to support your project with VR Builder and AI components